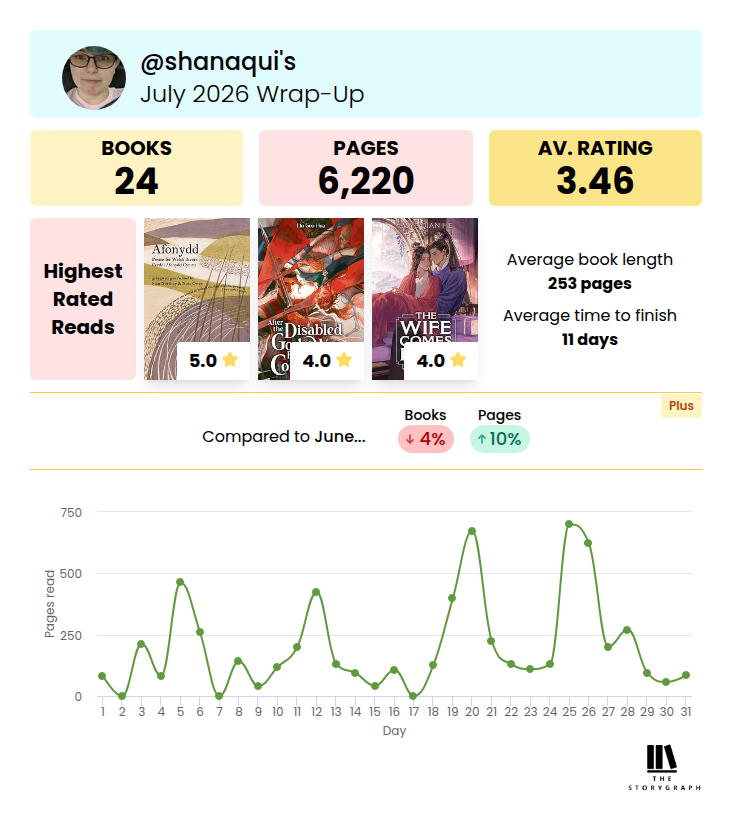
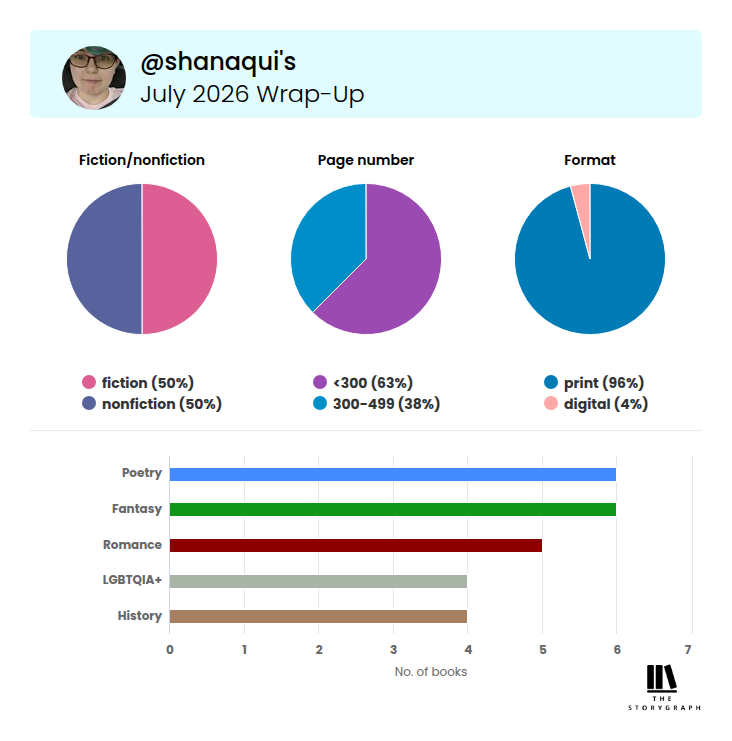
A Case of Fear and Favour
by Sally Smith
Genres: Crime, Historical Fiction, MysteryPages: 368
Series: The Trials of Gabriel Ward #3
Rating:

Synopsis:A priceless medieval book has been stolen from the Inner Temple. The librarian has been murdered at his desk. Once again, Sir Gabriel Ward KC must provide answers.
Gabriel meanwhile is preparing to represent a tiny sweetshop in Brighton brought to the brink of ruin by the postponed coronation of King Edward VII. Winning the case will save the sweetshop and change the law for ever. Yet for once he does not object to being pressed into acting as detective, because another miscarriage of justice may be on the cards.
The Temple authorities already have their prime suspects: Jitendra Shah, an Indian law student, and Lesley Roberts, the scandalously female assistant librarian, neither of whom fit the profile of a 'true' member of the Temple. Both were in the library at the time the murder must have taken place. Each claims not to have seen the other. At least one of them must be lying. But does this make them a killer?
Gabriel is convinced there is far more to this case than meets the eye. And in matters of murder, Gabriel is very seldom wrong…
I received a copy of this book for free in exchange for an honest review. This does not affect my opinion of the book or the content of my review.
When I got offered an eARC of Sally Smith’s latest Gabriel Ward book, A Case of Fear and Favour, there was noooo way I wasn’t jumping on it right away. I’ve loved the previous books and their loving but sometimes critical depiction of life in the Inner Temple, the ancient rules and regulations of the lawyers there, and of course, of Gabriel Ward himself, a bit stuffy but ultimately a very good man.
Over the course of the novels, Gabriel’s found himself getting more involved in the wider world beyond the Inner Temple, and that results here in him amazing everyone and himself by taking a pro bono case. I love that we get an explanatory note afterwards discussing the real law around that case and the historical precedent, which is carefully considered!
Other than Gabriel’s pro bono case, there’s also a mystery in the library of the Inner Temple, with the death of the librarian and the disappearance of some priceless documents. It turns out to be (unsurprisingly, given it’s a novel) not unconnected with Gabriel’s case, as well, and everything proceeds veeery neatly.
I enjoyed the introduction of the characters Lesley Roberts (a proto-feminist) and Jitendra (a figure based partially on some of the experiences of Gandhi), which tugged Gabriel out into the world just a little more, and opened his eyes to more injustices he’d never considered before.
Overall, a good entry to the series, and definitely a series I recommend to mystery lovers — especially if being set in a rather odd location (the Inner Temple, a long-standing inn of court) and around the time of the delayed coronation of King Edward VII appeals!
Rating: 4/5 (“really liked it”)